
Introduction: Why Most Chatbots Fail at Selling
Most chatbots are nothing more than search engines that can talk. They answer questions, retrieve information, and provide basic support—but they fundamentally fail at what businesses truly need: guiding customers toward purchase decisions. True sales AI requires an entirely different approach to training.
AI chatbots have gained tremendous importance in recent years and have become an indispensable tool for businesses. These intelligent systems are designed to simulate human conversations and provide automated responses to customer inquiries. The core of their functionality is based on advanced machine learning algorithms and artificial intelligence. However, the critical distinction lies in whether they're trained to merely answer or to actively sell and guide.
According to current statistics from Forbes, the AI market is expected to reach a volume of $407 billion by 2027. This underscores the growing importance of AI technologies, particularly chatbots, for companies across all industries. AI chatbots offer numerous benefits, including improved customer satisfaction through instant responses, reduced workload for customer service staff, and the ability to provide 24/7 support.
The functionality of AI chatbots is based on Natural Language Processing (NLP) and machine learning. They analyze user inputs, understand context, and generate appropriate responses. To do this effectively, they require extensive training data. This data is the key to a chatbot's performance and largely determines how well it can respond to various inquiries. But here's the crucial insight that most guides miss: the type of training data determines whether you build a support bot or a sales consultant.
Why Traditional Training Data Falls Short for Sales
Training data plays a central role in the development of AI chatbots. It encompasses a wide range of information, from simple question-answer pairs to complex conversation patterns. The more extensive and diverse this data, the better the chatbot can respond to different situations. The quality and relevance of training data directly influence the chatbot's ability to provide natural and helpful responses.
However, here's where most businesses go wrong: dumping FAQs and support documents creates a support bot, not a sales bot. A product consultant needs to understand not just 'What is Product X?' but critically 'Which product is better for customer need Y?' This consultative behavior—the ability to ask clarifying questions, understand preferences, and make recommendations—requires fundamentally different training approaches.
| Aspect | FAQ Support Bot | Product Sales Consultant |
|---|---|---|
| Data Source | Return policies, help articles, FAQs | Product features, customer needs, usage scenarios |
| Primary Goal | Answer questions reactively | Guide decisions proactively |
| Behavior Pattern | Wait for questions, provide answers | Ask questions, filter options, recommend |
| Training Focus | Text comprehension | Sales logic and product relationships |
| Success Metric | Query resolution rate | Conversion rate and basket value |
The distinction between general training (learning language patterns) and domain training (learning YOUR specific products and sales logic) is fundamental. Most resources focus on the former while businesses actually need the latter. Understanding the fundamentals of artificial intelligence provides the foundation, but applying it to sales requires a strategic shift in thinking.
Machine Learning Fundamentals for Sales Chatbots
Machine learning forms the foundation for developing modern AI chatbots. It enables these systems to learn from data and continuously improve their performance. However, for sales applications, the focus shifts from general language understanding to product-specific knowledge graphs and decision logic.
There are two main approaches in machine learning for chatbots: supervised and unsupervised learning. In supervised learning, the chatbot is trained with labeled datasets consisting of input-output pairs. This helps the system recognize patterns and respond correctly to similar queries. Unsupervised learning, on the other hand, allows the chatbot to independently discover structures in unlabeled data, which is particularly useful for processing complex language patterns.
The Learning Process Through Training Data
The learning process through training data is complex and iterative. First, large amounts of data are collected containing relevant conversations, questions, and answers. This data is then prepared and formatted for processing by the AI model. During training, the model learns to recognize patterns in the data and make predictions based on them.
An important aspect of training is continuous improvement and adaptation. After initial training, the chatbot is often tested in controlled environments and further optimized. Feedback from real users is collected and incorporated into the training process to constantly improve chatbot performance. This human-in-the-loop approach is essential for sales applications where subtle differences in recommendation quality can significantly impact conversion rates.
The functionality of AI chatbots is based on complex neural networks that can process and understand natural language. These networks are 'fed' with training data and learn to establish connections between words, sentences, and contexts. The more comprehensive and diverse the training data, the better the chatbot can respond to different inquiries and conduct natural conversations.

Step-by-Step: Training an AI Sales Consultant
Training a chatbot for product consultation requires a structured approach that goes beyond simply uploading documents. Here's how to build a system that actually sells:
Clean and structure your product feed from CSV/PIM systems. Separate attributes clearly.
Define product relationships, comparison logic, and 'better for X' mappings.
Train tone of voice, questioning patterns, and recommendation flows.
Implement filtering rules that connect customer needs to product attributes.
Test with real scenarios and iterate based on conversion performance.
Step 1: Building the Technical Foundation
The first step in the training process is careful preparation of training data. This involves cleaning errors, removing duplicates, and normalizing data. For text data, techniques such as tokenization, lemmatization, and stop word removal are often applied. This preprocessing is crucial to ensure high-quality input data for the model.
For sales chatbots specifically, you need to go beyond raw text. Your product feed—whether from a CSV export or a Product Information Management (PIM) system—must be structured with clearly separated attributes. A product description like 'Our quiet dishwasher' is less useful than structured data: 'noise_level: 42dB, category: dishwasher, attribute: quiet operation'.
Step 2: Encoding Sales Knowledge
This is where most training guides fall short. Teaching the bot attributes means creating explicit mappings between customer language and product specifications. When a customer says 'I need something quiet,' the bot must understand that 'quiet' maps to 'noise_level < 45dB' for appliances or 'typing_sound: silent' for keyboards.
The choice of the right model and architecture is a critical step. For modern AI chatbots, advanced architectures like Transformer or BERT are often used. Model size and complexity must be carefully adapted to the chatbot's specific requirements and available resources. Smaller models may suffice for simple tasks, while more complex applications require more powerful architectures.
Step 3: Designing Conversational Flow
A sales consultant doesn't just answer—they ask. Training conversational flow means teaching the bot to proactively gather information: 'What's your budget range?' 'Do you prefer brand A or brand B?' 'Will this be for home or office use?' This proactive questioning transforms a reactive FAQ bot into an active sales agent.
Tone of voice training is equally important. German B2B buyers often expect a more formal, precise communication style (seriös), while B2C e-commerce might benefit from a friendlier, more casual approach (locker). The evolution of chatbots to conversational AI shows how these nuances have become increasingly sophisticated.
Types of Training Data for Chatbots
Understanding Training Data Types
In the development of AI chatbots, various types of training data play a decisive role. Each data type has its specific advantages, disadvantages, and application areas. Here we examine the most important categories:
Text-Based Data
Text-based data forms the foundation for training AI chatbots. It includes written texts such as articles, books, websites, and conversation transcripts. This data helps the chatbot understand and generate language.
Advantages: Easily available, diverse, good for general language understanding.
Disadvantages: May be outdated or inaccurate, often require extensive preprocessing.
Application areas: General conversations, information queries, text analysis.
Dialog Data
Dialog data consists of recorded conversations between humans or between humans and existing chatbots. They are particularly valuable for learning natural conversation flows.
Advantages: Realistic conversation structures, capturing context and nuances.
Disadvantages: Difficult to obtain in large quantities, may raise privacy concerns.
Application areas: Customer service chatbots, virtual assistants.
Domain-Specific Data
This data is tailored to specific fields or industries. It includes technical terms, specific processes, and expert knowledge from a particular area.
Advantages: High accuracy in specialized fields, improved performance on specialized tasks.
Disadvantages: Limited availability, often require expert knowledge for preparation.
Application areas: Medical advice, technical support, legal assistance.
Multimodal Data
Multimodal data combines text with other formats like images, audio, or video. They enable chatbots to process and understand more complex information.
Advantages: Enable more versatile interactions, improve context understanding.
Disadvantages: Technically demanding to process, require special model architectures.
Application areas: Visual product consultation, speech recognition in customer service chatbots.
Data Collection and Preparation Best Practices
The quality and relevance of training data are crucial for an AI chatbot's performance. The process of data collection and preparation includes several important steps:
Sources for Training Data
Selecting suitable data sources is the first step in creating an effective training dataset. Here are some options:
- Public datasets: Freely available collections of texts, dialogs, or domain-specific information.
- Internal company data: Customer conversations, emails, support tickets, or product descriptions.
- Web scraping: Automated extraction of data from websites, forums, or social media.
- Crowdsourcing: Using platforms to collect specific datasets from a large number of people.
When selecting sources, it's important to pay attention to quality, relevance, and legal aspects. Using vector databases can help efficiently manage and retrieve large amounts of training data.
Data Cleaning and Normalization
Raw data often needs to be cleaned and normalized to improve quality:
Cleaning: Removing duplicates, correcting spelling errors, eliminating irrelevant information.
Normalization: Standardizing formats, dates, and units of measurement, converting to a uniform format.
These steps are crucial to reduce inconsistencies and increase training reliability.
Data Augmentation and Extension
Various techniques can be applied to increase the diversity and quantity of training data:
Paraphrasing: Reformulating existing texts to increase variance.
Translation: Using translation tools to create multilingual datasets.
Synthetic data generation: Using AI models to create new, realistic examples.
These methods help improve the chatbot's robustness and generalization ability by confronting it with a greater variety of inputs.
Careful data collection and preparation lays the foundation for a powerful AI chatbot. It requires time and resources but is crucial for project success. With high-quality and well-prepared data, the training process can be designed more efficiently and effectively, ultimately leading to a chatbot that can better respond to user needs.
Stop training FAQ bots. Start building AI sales consultants that understand your products and guide customers to purchase decisions.
Start Your Free TrialThe Training Process: Technical Deep Dive
Training an AI chatbot is a complex process that includes several steps. This section illuminates the individual phases of the training process and explains technical details for deeper understanding.
Data Preparation and Preprocessing
The first step in the training process is careful preparation of training data. This involves cleaning errors, removing duplicates, and normalizing data. For text data, techniques such as tokenization, lemmatization, and stop word removal are often applied. This preprocessing is crucial to ensure high-quality input data for the model.
Model Selection and Architecture
The choice of the right model and architecture is a critical step. For modern AI chatbots, advanced architectures like Transformer or BERT are often used. Model size and complexity must be carefully adapted to the chatbot's specific requirements and available resources. Smaller models may suffice for simple tasks, while more complex applications require more powerful architectures.
Training Process and Hyperparameter Optimization
The actual training process involves iteratively adjusting model parameters based on training data. Hyperparameter optimization plays a central role. Important hyperparameters include learning rate, batch size, and number of training iterations. Techniques like cross-validation and grid search help fine-tune these parameters to achieve the best possible performance.
During training, the model is continuously confronted with training data and learns to recognize patterns and relationships. Modern training methods like transfer learning can accelerate the process by building on pre-trained models and adapting them to the specific task.
Validation and Testing
After completing training, it's crucial to verify model performance. This is done through validation with a separate dataset that wasn't used in training. Validation helps identify problems like overfitting, where the model has learned the training data too precisely and doesn't generalize well to new data.
Finally, the model is evaluated with a test dataset to assess its performance in real scenarios. Metrics such as accuracy, precision, and recall provide insight into the quality of the trained chatbot. With unsatisfactory results, the process can be repeated with adjusted parameters or additional data.
The entire training process often requires multiple iterations and adjustments until a satisfactory result is achieved. The introduction of an AI chatbot is therefore a dynamic process that requires continuous improvement and fine-tuning.
Training vs. Fine-Tuning: What Do You Actually Need?
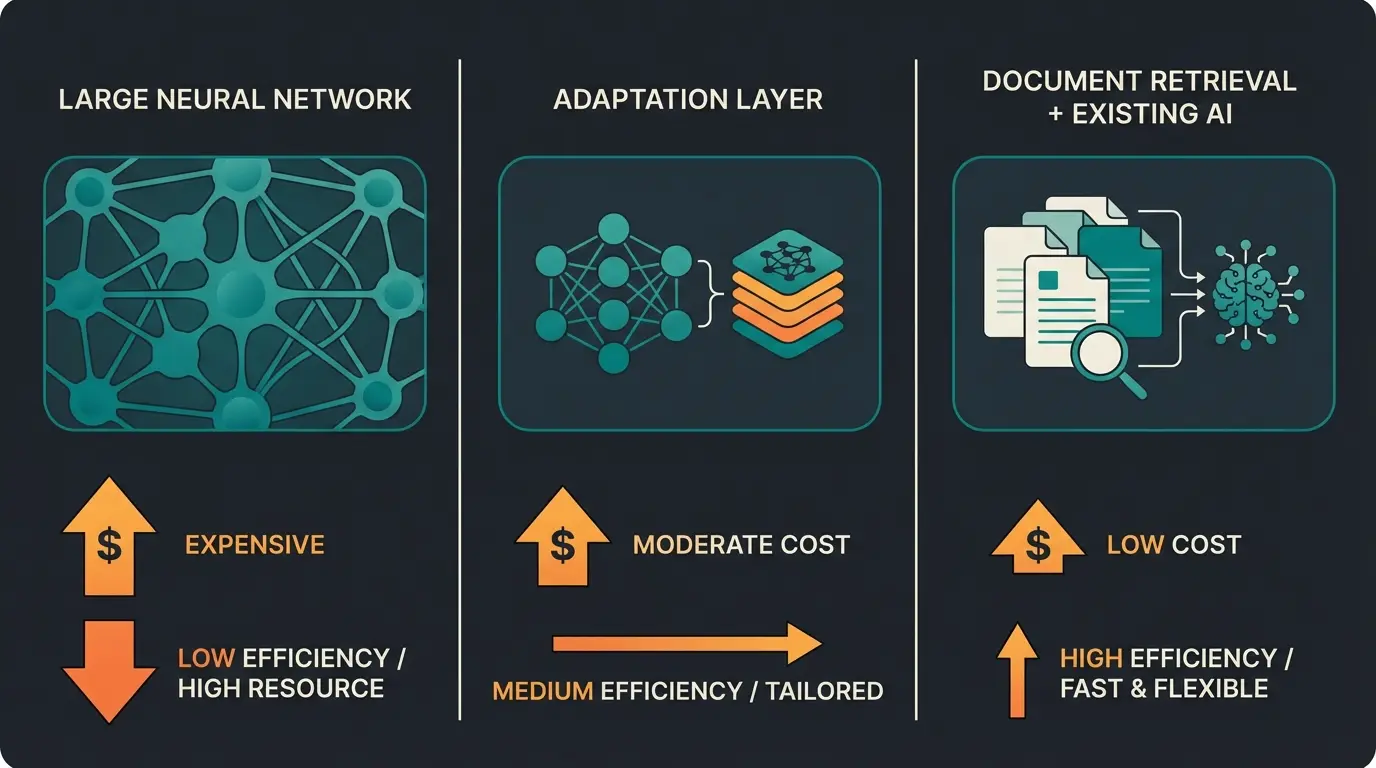
One of the most common misconceptions in chatbot development is the belief that you need to retrain an entire Large Language Model (LLM) from scratch. This is expensive, time-consuming, and usually unnecessary. Let's clarify the distinction:
Training a new LLM from scratch—rarely necessary for most businesses
Adapting a pre-trained model to your domain—useful for specific behaviors
Retrieval-Augmented Generation grounded in your product data—often the best approach
For most e-commerce and product consultation applications, Retrieval-Augmented Generation (RAG) is the optimal approach. RAG allows you to ground a pre-trained model in your specific product data without the expense of fine-tuning. The model retrieves relevant product information at query time and generates responses based on factual data—dramatically reducing hallucination risks.
This distinction matters particularly for addressing a critical fear of e-commerce managers: hallucination in sales. When a bot invents product features, it doesn't just create bad customer experience—it creates legal liability. RAG architectures, properly implemented, ensure the bot sticks to verified product facts.
Challenges in Chatbot Training
Training AI chatbots comes with various challenges that are both technical and ethical in nature. This section presents common problems and possible solutions.
Handling Ambiguity and Context
One of the biggest challenges in training chatbots is dealing with linguistic ambiguities and context-dependent meanings. Human communication is often nuanced and highly context-dependent. Chatbots must learn to recognize subtle differences in meaning and respond appropriately.
To address this challenge, advanced NLP (Natural Language Processing) techniques are used. Contextual embeddings and attention mechanisms, as used in modern Transformer models, help the chatbot better understand context and generate more precise responses.
Bias in Training Data
Another important challenge is dealing with bias in training data. AI models can unintentionally adopt prejudices or discriminatory patterns from training data, leading to problematic outputs.
To address this problem, it's important to:
- Diversity: Ensure training data represents a broad and representative sample.
- Review: Regularly review training data for possible biases.
- Balance: Actively balance imbalances in the data.
- Ethics guidelines: Implement clear ethical guidelines for data collection and use.
Scaling and Computational Requirements
Training large AI models for chatbots requires significant computational resources. Scaling training to large datasets and complex model architectures can be a technical and financial challenge.
Solutions for this challenge include using distributed training on high-performance computers, utilizing cloud computing resources, and developing more efficient training algorithms. Techniques like model compression and quantization can help reduce model size and optimize computational effort without significantly affecting performance.
Addressing these challenges requires an interdisciplinary approach that combines technical know-how with ethical considerations and practical feasibility. Only in this way can AI chatbots be developed that are not only powerful but also responsible and user-friendly.
GDPR Compliance and Data Security Best Practices
For German and EU markets, data protection isn't optional—it's foundational. This represents a significant differentiation opportunity for businesses that can demonstrate data sovereignty and compliance.
Data Privacy Aspects for Training Data
Protecting personal data is of utmost importance when using training data for AI chatbots. According to Forbes research, over 75% of consumers are concerned about misinformation from AI. To address these concerns, the following aspects should be considered:
- Anonymization: Personal information in training data must be anonymized.
- Consent: Explicit consent should be obtained when using user data for training.
- Data security: Robust security measures to protect training data are essential.
- Data minimization: Only data necessary for training should be collected and used.
- Hosting location: For German B2B buyers, hosting in Germany/EU provides critical trust signals.
Responsible Use of AI Technology
Responsible use of AI technology requires a balance between innovation and ethical principles. Companies should develop clear guidelines for using AI chatbots and review them regularly. It's important to identify potential risks and implement strategies to mitigate them.
The development of AI chatbots requires not only technical know-how but also a deep understanding of ethical and data protection implications. Only through a responsible approach can companies fully exploit this technology's potential while gaining and maintaining user trust.
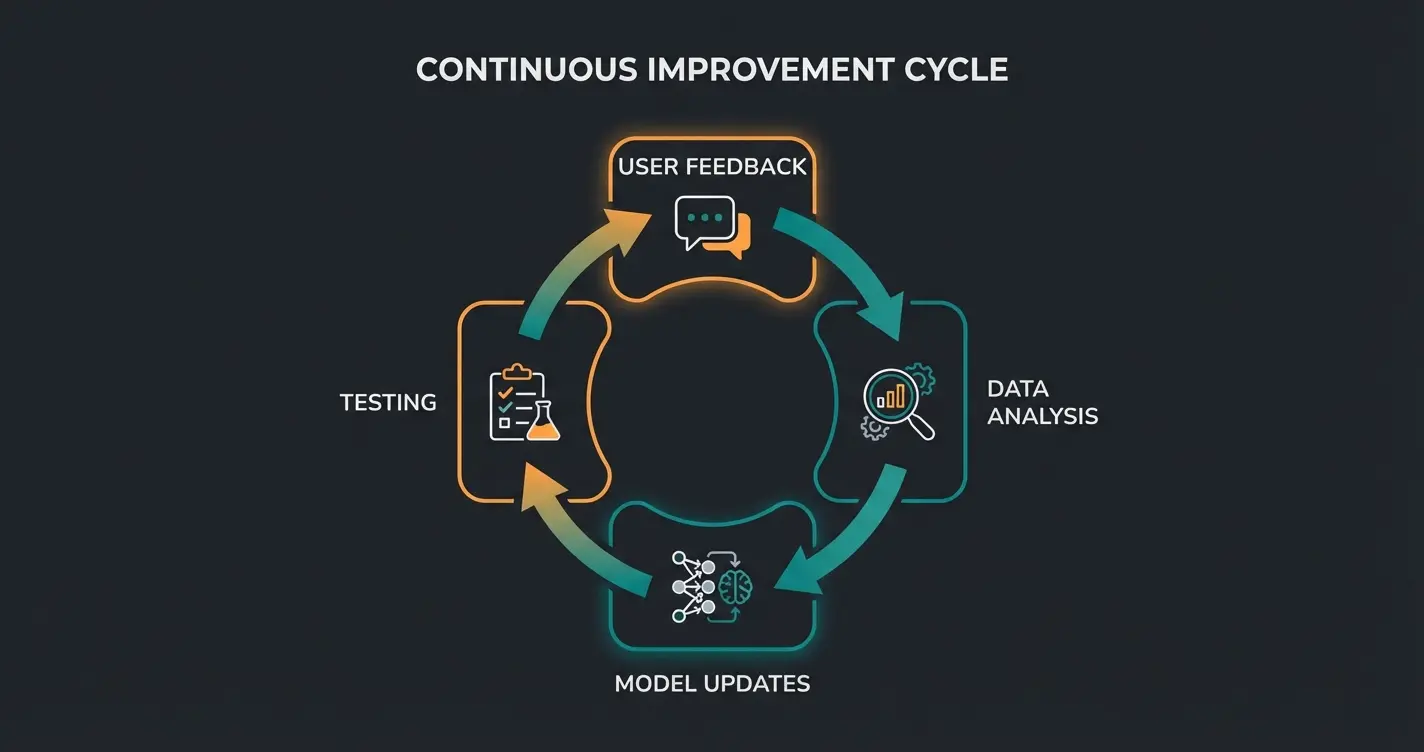
Optimization and Fine-Tuning Strategies
Developing an AI chatbot is a continuous process that doesn't end with initial training. To improve chatbot performance and relevance, ongoing optimizations and fine-tuning are required. Here are some important methods for improving chatbot performance:
Continuous Improvement Through User Feedback
User feedback is an invaluable source for chatbot development. By analyzing user ratings, comments, and frequently asked questions, weaknesses can be identified and addressed. Conversational AI enables analyzing user behavior and adapting the chatbot accordingly.
Transfer Learning and Fine-Tuning
Transfer learning is an effective method for optimizing AI chatbots. A pre-trained model is used as a starting point and fine-tuned to the specific requirements of the use case. This technique makes it possible to benefit from already learned capabilities while integrating domain-specific knowledge.
A/B Testing for Chatbot Responses
Through A/B testing, different versions of chatbot responses can be compared. This helps identify the most effective formulations and interaction patterns. The results of these tests flow directly into chatbot optimization.
Regular Knowledge Base Updates
To keep the chatbot up to date, regular updating of the knowledge base is essential. This includes integrating new information, products, or services as well as adapting to changing customer needs and market trends.
Ethical Considerations in AI Chatbot Deployment
In developing and deploying AI chatbots, ethical considerations and data protection aspects play a central role. It's important to consider these issues from the beginning to build user trust and comply with legal requirements.
Ethical Questions in AI Chatbot Deployment
Using AI chatbots raises various ethical questions that must be carefully weighed:
- Transparency: Users should be informed that they're interacting with an AI system.
- Fairness: The chatbot must be free from prejudices and discrimination.
- Accountability: It must be clear who is responsible for the chatbot's actions.
- Human control: A mechanism for human oversight and intervention should be in place.
The Future of Sales-Focused AI Training
Training AI chatbots is a complex and dynamic process that is constantly evolving. The quality of training data plays a decisive role in chatbot performance and reliability. Through careful data selection, preparation, and continuous optimization, companies can develop AI chatbots that not only work efficiently but also provide valuable support in customer service.
Current statistics from Forbes Advisor underscore the growing importance of AI and chatbots:
- Market size: The AI market is expected to grow to $407 billion by 2027.
- Economic impact: AI could increase US GDP by 21% by 2030.
- User acceptance: ChatGPT gained one million users within the first five days of release.
- Business perspective: 64% of companies expect AI to increase productivity.
These numbers illustrate the enormous potential of AI chatbots for companies across various industries. At the same time, we face important challenges:
- Ethics: Responsible handling of AI technologies remains a central task.
- Data protection: Security and protection of user data must be guaranteed.
- Transparency: Users should understand when they're interacting with an AI system.
- Further development: Continuous research and innovation are needed to improve AI chatbot capabilities.
For companies that want to use or develop AI chatbots, it's important to view this technology as a complement to human customer service. AI chatbots can take over repetitive tasks and be available around the clock, while human employees can focus on more complex inquiries and building personal customer relationships.
The future of AI chatbots promises exciting developments:
- Multimodal interaction: Integration of text, voice, and visual elements for more natural conversations.
- Improved context processing: Deeper understanding of nuances and implicit meanings in communication.
- Personalization: Even more individual adaptation to the needs and preferences of individual users.
- Industry-specific solutions: Tailored AI chatbots for specific industries and use cases.
Frequently Asked Questions About AI Chatbot Training
Training typically refers to building a model from scratch using large datasets, which is resource-intensive and expensive. Fine-tuning means adapting a pre-trained model to your specific domain with much less data and cost. For most business applications, you don't need either—Retrieval-Augmented Generation (RAG) lets you ground existing models in your product data without expensive training.
Quality trumps quantity. For product consultation chatbots, a well-structured product feed with 500-1000 products and clear attributes often outperforms 10,000 unstructured documents. Focus on structured data: product specifications, comparison logic, and customer need mappings rather than raw text volume.
Implement a RAG (Retrieval-Augmented Generation) architecture that grounds responses in your verified product database. For critical product specifications, use deterministic retrieval rather than generation—the bot should quote your database, not improvise. Regular validation against your product catalog and human-in-the-loop review for edge cases are essential.
Under GDPR, you need explicit consent to use personal data for AI training. Best practices include anonymizing all personal identifiers, obtaining clear consent for data use, implementing data minimization principles, and hosting data within EU jurisdiction. Consider synthetic data generation as an alternative for training conversational patterns.
Timeline depends heavily on your approach. RAG implementation with clean product data: 2-4 weeks. Fine-tuning a pre-trained model: 4-8 weeks including data preparation. The ongoing optimization cycle—incorporating feedback, updating product data, improving conversation flows—should be continuous and never truly ends.
Conclusion: Building Bots That Sell, Not Just Answer
The fundamental difference between a support chatbot and a sales consultant comes down to training philosophy. Support bots are trained to answer questions; sales consultants are trained to guide decisions. This requires different data, different architectures, and different success metrics.
In conclusion, training AI chatbots is a fascinating and future-oriented field. With the right balance of technological innovation, ethical responsibility, and human empathy, AI chatbots can become valuable tools that provide real added value for both companies and customers.
The key insights for building effective sales AI: prioritize structured product data over document dumps, implement sales logic that maps customer needs to product attributes, ensure determinism in product specifications to prevent hallucination, and establish continuous improvement cycles based on conversion performance—not just satisfaction scores.
Stop building FAQ bots that answer questions. Start building AI sales consultants that understand your products, ask the right questions, and guide customers to confident purchase decisions.
Build Your Sales AI Now
Kevin is CTO and co-founder of Qualimero. As an AI architect with over 15 years of experience as CTO and CPO in the tech industry, he designs the AI systems that automate tens of thousands of customer interactions daily for Qualimero's clients — reliably, securely, and at scale.
