
Was ist KI-Datenannotation und warum ist sie entscheidend?
KI ist nur so intelligent wie ihre Lehrer. Dieser Grundsatz fasst das gesamte Thema der KI-Datenannotation in einem Satz zusammen. Ohne präzise gekennzeichnete Trainingsdaten kann selbst das ausgefeilteste Machine-Learning-Modell keine sinnvollen Ergebnisse liefern. Die Datenkennzeichnung – auch Labeling genannt – bildet das Fundament jeder erfolgreichen KI-Implementierung.
Stell dir vor, du möchtest einem Kind beibringen, einen Apfel von einer Birne zu unterscheiden. Du zeigst ihm Bilder und sagst: 'Das ist ein Apfel, das ist eine Birne.' Genau so funktioniert KI-Training. Die annotierten Daten sind die Lernkarten, mit denen das Modell trainiert wird. Je präziser und umfangreicher diese Kennzeichnungen sind, desto besser lernt die KI, wie sie in den Grundlagen des KI-Trainings beschrieben werden.
Doch hier liegt ein fundamentales Problem: Die meisten Unternehmen und Tools konzentrieren sich auf das Erkennen von Objekten – ein Auto, eine Katze, ein Verkehrsschild. Was aber, wenn deine KI nicht nur erkennen, sondern beraten soll? Wenn sie verstehen muss, warum ein Kunde ein bestimmtes Produkt braucht? Hier zeigt sich die entscheidende Lücke im aktuellen Markt der KI-Datenannotation.
Der Großteil eines ML-Projekts fließt in die Datenvorbereitung
'Garbage in, garbage out' – Modellqualität hängt von Datenqualität ab
Domänen-Experten annotieren beratungsrelevante Daten präziser
Die verschiedenen Arten der Datenkennzeichnung im Überblick
Um zu verstehen, wo die Grenzen herkömmlicher Annotationsansätze liegen, müssen wir zunächst die verschiedenen Typen der Datenkennzeichnung betrachten. Jeder Typ hat seine eigenen Anforderungen, Tools und Herausforderungen – und nicht alle sind gleichermaßen für jede Anwendung geeignet.
Computer Vision: Bounding Boxes und Segmentierung
Der bekannteste Bereich der KI-Datenannotation ist die Bildverarbeitung. Hier werden Objekte in Bildern oder Videos markiert – sei es durch Bounding Boxes (rechteckige Rahmen um Objekte), Segmentierung (pixelgenaue Markierung) oder Klassifizierung (Zuordnung zu Kategorien). Diese Art der Annotation dominiert Anwendungen wie autonomes Fahren, medizinische Bildgebung und industrielle Qualitätskontrolle.
Tools wie Labelbox wurden primär für diese Anwendungsfälle entwickelt. Sie bieten hervorragende Werkzeuge für die Markierung visueller Elemente und können große Teams von Annotatoren effizient koordinieren. Für die Erkennung eines Stoppschilds oder die Segmentierung eines Tumors in einem MRT-Bild sind sie die optimale Wahl.
Einfache NLP-Annotation: Sentiment und Klassifizierung
Im Bereich der Textanalyse beginnt die Annotation oft mit einfachen Kategorisierungen. Ein Text wird als 'positiv', 'negativ' oder 'neutral' eingestuft. Eine E-Mail wird als 'Spam' oder 'kein Spam' klassifiziert. Diese binären oder kategorialen Annotationen lassen sich relativ einfach automatisieren und skalieren.
Die praktische KI-Implementierung zeigt jedoch, dass diese oberflächliche Kategorisierung für viele Geschäftsanwendungen nicht ausreicht. Zu wissen, dass ein Kunde 'unzufrieden' ist, hilft wenig, wenn du nicht verstehst, warum er unzufrieden ist und was er eigentlich braucht.
Konversations-Annotation: Die wahre Herausforderung
Hier betreten wir das Terrain, das die meisten Standard-Tools und Anleitungen vernachlässigen: die Annotation von Dialogdaten für beratende KI-Systeme. Es geht nicht mehr nur darum, was gesagt wurde, sondern warum es gesagt wurde, welche Absicht dahintersteht und welche Aktion daraus folgen sollte.
Eine Konversations-Annotation muss erfassen: die Kundenintention (sucht, vergleicht, kauft), kontextuelle Einschränkungen (Budget, Zeitrahmen, Präferenzen), Produktattribute (Größe, Farbe, Material) und die Qualität der Antwort (Hat die KI die richtige Folgefrage gestellt?). Diese Multi-Layer-Annotation erfordert ein völlig anderes Vorgehen als das simple Markieren von Objekten in Bildern.
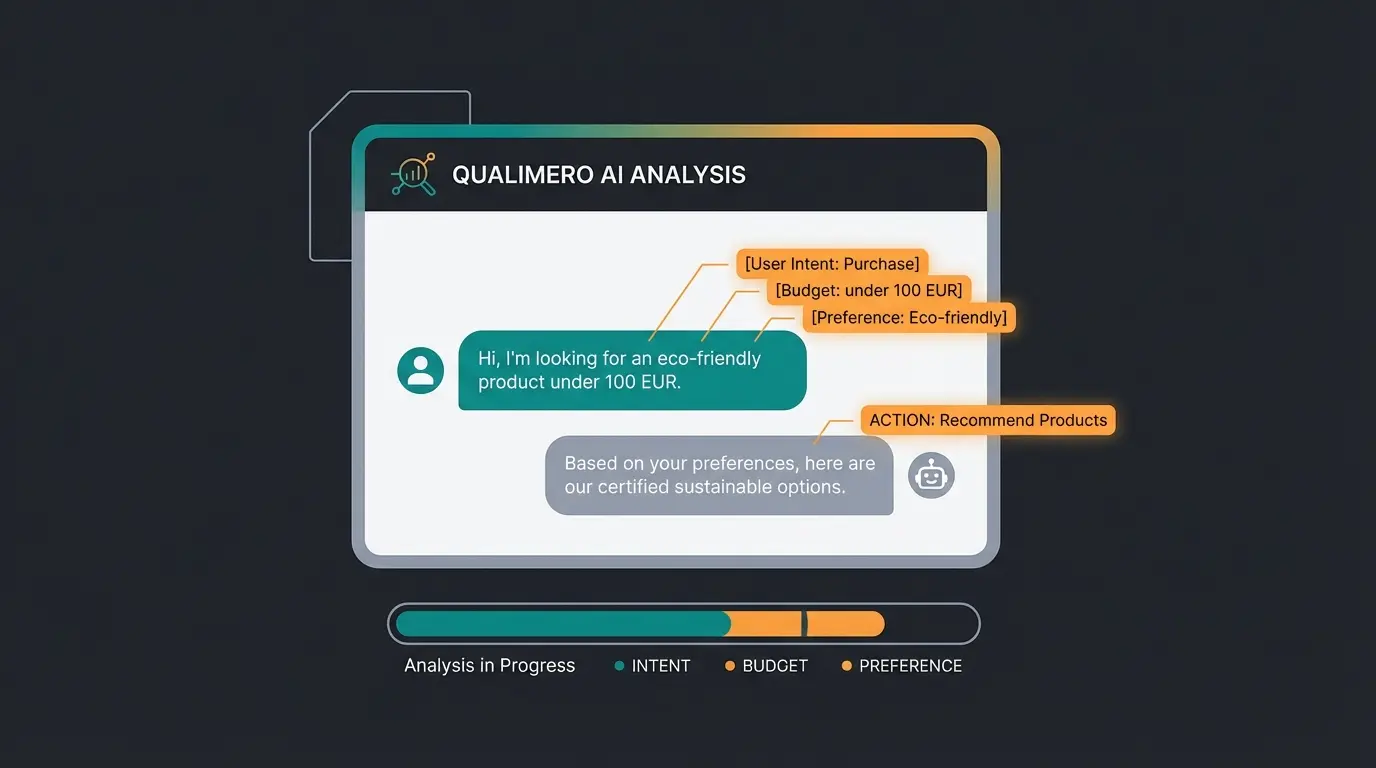
Die Hierarchie des KI-Verständnisses
Um die Unterschiede zwischen verschiedenen Annotationsansätzen greifbar zu machen, hilft eine Betrachtung der verschiedenen Ebenen des KI-Verständnisses. Jede Ebene erfordert andere Annotationsstrategien und -qualitäten.
Die KI identifiziert: 'Das ist ein Auto.' Standard-Annotation mit Bounding Boxes und Labels reicht aus.
Die KI versteht: 'Das ist ein schönes Auto.' Einfache Kategorisierung (positiv/negativ) wird annotiert.
Die KI berät: 'Dieses Auto passt zu Ihren Familienbedürfnissen, weil...' Experten-Annotation mit Kontext erforderlich.
Die meisten Unternehmen und Tools operieren auf den Ebenen 1 und 2. Doch für eine KI-gestützte Produktberatung, die tatsächlich beraten und nicht nur antworten soll, ist Ebene 3 entscheidend. Und genau hier versagen generische Annotationsansätze.
Labelbox und Co: Was Standard-Tools leisten
Labelbox ist eine führende KI-Datenkennzeichnungsplattform, die sich als Standard für hochqualitative Datenaufbereitung im Bereich Machine Learning etabliert hat. Die Plattform ermöglicht Unternehmen und Entwicklern die präzise Kennzeichnung, Verwaltung und Optimierung von Trainingsdaten für KI-Modelle. Im Zentrum steht dabei die effiziente Zusammenarbeit von Teams bei der Datenvorbereitung.
Das Datenmanagement-System
Das zentrale Datenmanagement-System von Labelbox bietet eine strukturierte Umgebung für die Organisation und Speicherung von Trainingsdaten. Teams können parallel an Projekten arbeiten, während das integrierte Versionierungssystem alle Änderungen nachvollziehbar dokumentiert. Die intuitive Oberfläche erleichtert die Zusammenarbeit zwischen verschiedenen Abteilungen und externen Annotatoren.
KI-gestützte Annotationstools
Die KI-gestützten Annotationstools beschleunigen den Kennzeichnungsprozess durch automatische Vorschläge und Massenverarbeitung. Entwickler können benutzerdefinierte Labels erstellen und Annotationsrichtlinien festlegen. Die Plattform unterstützt verschiedene Annotationstypen wie Bounding Boxes, Segmentierung und Klassifizierung – alles Werkzeuge, die primär für visuelle Daten optimiert wurden.
Integrierte Qualitätskontrolle
Ein umfassendes Qualitätssicherungssystem überwacht kontinuierlich die Genauigkeit der Datenkennzeichnung. Automatische Prüfprozesse identifizieren Unstimmigkeiten und ermöglichen schnelle Korrekturen. Performance-Metriken geben Einblick in die Effizienz des Annotationsteams und die Qualität der erzeugten Trainingsdaten.
Technische Integration: Was Tools wie Labelbox bieten
Die technische Integration solcher Plattformen erfordert eine strukturierte Herangehensweise. Sie bieten verschiedene Möglichkeiten zur Einbindung in bestehende Systeme und Arbeitsabläufe, die für standardisierte ML-Projekte gut funktionieren.
Systemvoraussetzungen und Setup
Labelbox läuft als Cloud-basierte Lösung und benötigt minimale lokale Ressourcen. Ein moderner Webbrowser und stabile Internetverbindung sind die Basis. Für größere Datensätze empfiehlt sich eine Bandbreite von mindestens 50 Mbit/s. Die Plattform unterstützt alle gängigen Betriebssysteme wie Windows, macOS und Linux.
API-Anbindung für ML-Pipelines
Die REST-API ermöglicht eine nahtlose Integration in bestehende ML-Pipelines. Die API unterstützt sowohl JSON als auch GraphQL für flexible Abfragen. Diese Standardisierung macht es einfach, annotierte Daten automatisch in Trainingsprozesse einzuspeisen – ein wichtiger Faktor für die Skalierbarkeit von KI-Projekten.
Unterstützte Datenformate
Standard-Annotationsplattformen verarbeiten eine breite Palette an Dateiformaten. Für Bilddaten werden JPG, PNG und TIFF unterstützt. Textdaten können als TXT, CSV oder JSON importiert werden. Videoformate wie MP4 und MOV sind ebenfalls kompatibel. Die Plattformen konvertieren Daten automatisch in das optimale Format für die Verarbeitung.
Sicherheit und Compliance
Führende Plattformen setzen auf mehrschichtige Sicherheitsmaßnahmen. SSL-Verschlüsselung schützt alle Datenübertragungen. Rollenbasierte Zugriffskontrollen ermöglichen eine granulare Steuerung der Benutzerrechte. Regelmäßige Sicherheitsaudits und SOC 2 Typ II Zertifizierung garantieren höchste Sicherheitsstandards – essenziell für sensible Unternehmensdaten.
Skalierung bei wachsenden Anforderungen
Die elastische Infrastruktur passt sich automatisch an steigende Datenmengen an. Performance-Monitoring-Tools helfen bei der Optimierung. Bei Bedarf können zusätzliche Ressourcen schnell bereitgestellt werden. Diese Skalierbarkeit ist ein zentraler Vorteil cloud-basierter Lösungen.
Wo Standard-Labeling an seine Grenzen stößt
Trotz aller Stärken generischer Annotationstools zeigen sich deutliche Limitierungen, sobald es um beratungsintensive KI-Anwendungen geht. Das Problem liegt nicht in der technischen Umsetzung, sondern im fundamentalen Ansatz.
Das Problem des Crowd-Labelings
Viele Annotationsprojekte setzen auf Crowd-Sourcing: Tausende Clickworker labeln Daten nach einfachen Richtlinien. Für die Erkennung eines Stoppschilds funktioniert das hervorragend – jeder kann ein Stoppschild identifizieren. Aber kann ein beliebiger Clickworker erkennen, ob eine KI-Antwort eine gute Produktberatung darstellt?
Ein Beispiel: Ein Kunde schreibt 'Es ist kalt.' Ein Standard-Annotator würde dies als 'Wetterbeschreibung' oder 'Fakt' labeln. Ein Experte für Produktberatung erkennt jedoch: Dies ist ein Bedürfnis – der Kunde sucht wahrscheinlich nach einer warmen Jacke oder Winterbekleidung. Diese semantische Tiefe geht bei generischem Labeling verloren.
| Kundenaussage | Standard-Annotation | Beratungsorientierte Annotation |
|---|---|---|
| 'Es ist kalt.' | Wetter / Faktische Aussage | Bedürfnis: Warme Kleidung / Winterausrüstung |
| 'Ich brauche etwas Günstiges.' | Sentiment: Neutral | Constraint: Budget-limitiert, Preis-sensitiv |
| 'Haben Sie das in Grün?' | Farbpräferenz | Kaufintention + Attribut: Farbe = Grün |
| 'Mein Kind ist 5 Jahre alt.' | Altersangabe / Fakt | Kontext: Kindergröße, Altersgruppe 4-6 Jahre |
Multi-Turn-Dialoge: Die ungelöste Herausforderung
Standard-Textannotation betrachtet einzelne Sätze oder Dokumente isoliert. Doch echte Beratungsgespräche sind Multi-Turn-Dialoge: Der Kontext baut sich über mehrere Nachrichten auf, frühere Aussagen beeinflussen spätere Interpretationen, und die Qualität einer Antwort hängt davon ab, ob die KI die richtige Folgefrage gestellt hat.
Tools wie Labelbox sind für die Visualisierung und Annotation solcher Dialogbäume nicht optimiert. Sie können Text markieren, aber sie bieten keine nativen Werkzeuge für die Annotation von Gesprächsflüssen, Intent-Sequenzen oder der Qualität von Beratungslogik.
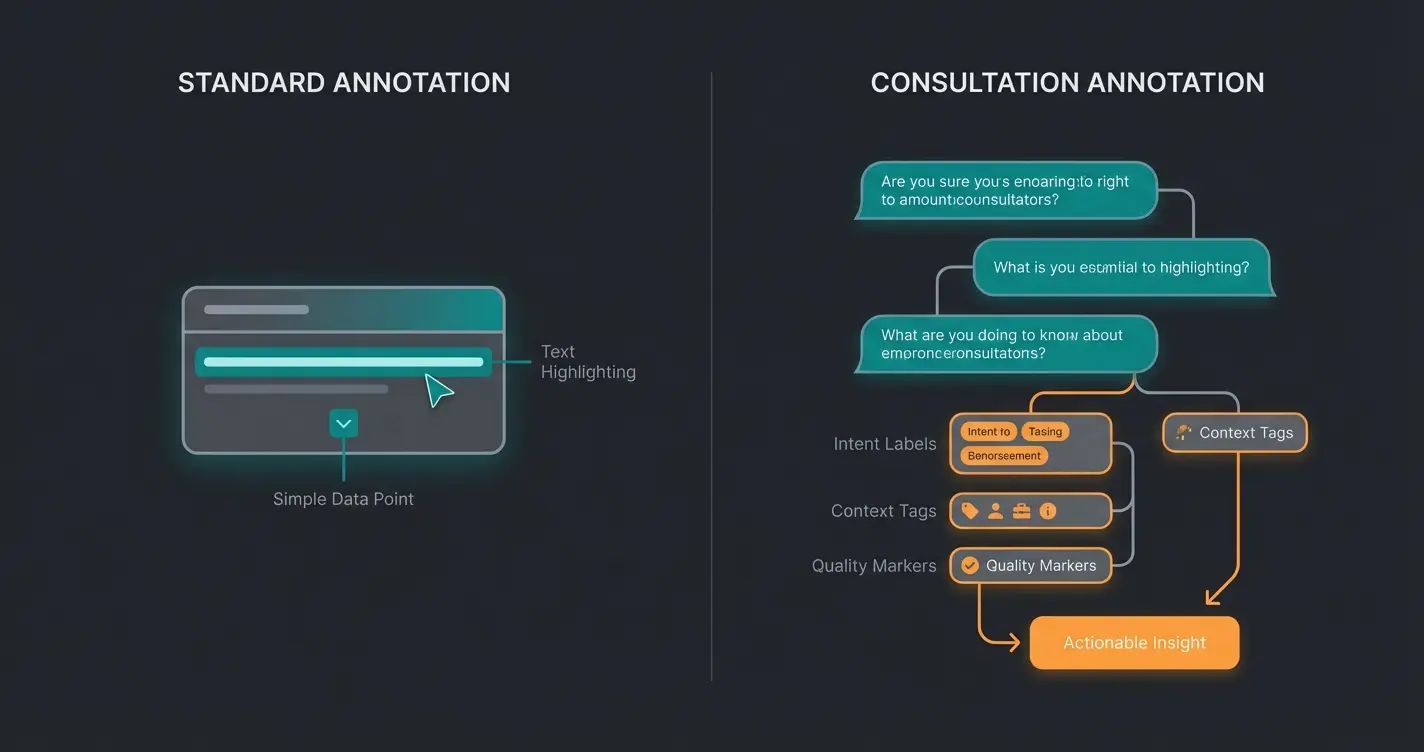
Qualität vor Quantität: Der Experten-Ansatz
Während die Industrie oft über 'Big Data' spricht, zeigt die Praxis: Für beratende KI-Systeme sind 'Smart Data' entscheidend. 100 von Domänen-Experten annotierte Dialoge können mehr Wert liefern als 10.000 generisch gelabelte Texte.
Warum Domänen-Expertise unverzichtbar ist
Ein Fashion-Experte erkennt sofort, dass eine Empfehlung für 'schmale Schnitte' bei einem Kunden mit 'sportlicher Figur' sinnvoll ist. Ein Mode-unkundiger Annotator sieht nur zwei Textbausteine ohne semantische Verbindung. Diese Expertenwissen fließt in die Annotationsqualität ein und verbessert direkt die Modellleistung.
Die automatisierte Leadgenerierung zeigt ähnliche Muster: Nur wer versteht, was einen qualifizierten Lead ausmacht, kann entsprechende Daten sinnvoll kennzeichnen. Generische Annotation verpasst die Nuancen, die den Unterschied zwischen einem interessierten Besucher und einem kaufbereiten Kunden ausmachen.
Human-in-the-Loop: Der unverzichtbare Faktor
Trotz aller Fortschritte in der automatisierten Annotation bleibt der Mensch unverzichtbar – besonders bei komplexen Beratungsszenarien. Human-in-the-Loop bedeutet nicht nur menschliche Qualitätskontrolle, sondern aktive Einbindung von Experten in den Annotationsprozess. Sie definieren die Richtlinien, trainieren das Team und validieren schwierige Fälle.
Der Prozess: Von Rohdaten zur Modelloptimierung
Ein strukturierter Annotationsprozess bildet das Rückgrat erfolgreicher KI-Projekte. Die Schritte unterscheiden sich je nach Anwendungsfall, doch für beratungsorientierte Systeme gelten besondere Anforderungen an Qualität und Expertise.
Echte Kundendialoge, Support-Anfragen und Beratungsgespräche sammeln – keine synthetischen Beispiele
Mit Domänen-Experten festlegen: Was ist gute Beratung? Welche Intents sind relevant?
Geschulte Fachleute annotieren mit voller Kontexttiefe – Intent, Attribute, Qualität
Mehrfach-Validierung, Inter-Annotator-Agreement, Feedback-Schleifen
Modell-Feedback nutzen, um Annotationsrichtlinien zu verfeinern
Schritt 1: Datensammlung aus echten Gesprächen
Der Grundstein jeder guten Annotation sind echte Daten. Für beratende KI-Systeme bedeutet das: echte Kundengespräche, nicht synthetisch generierte Beispiele. Diese Rohdaten enthalten die natürlichen Variationen, Umgangssprache und unerwarteten Wendungen, die ein robustes Modell verstehen muss.
Schritt 2: Annotationsrichtlinien mit Experten
Bevor ein einziger Datenpunkt annotiert wird, müssen klare Richtlinien existieren. Was macht eine 'gute Beratung' aus? Welche Customer Intents sind für dein Geschäft relevant? Diese Fragen können nur Domänen-Experten beantworten – nicht generische Labeling-Teams.
Schritt 3: Die eigentliche Annotation
Mit den definierten Richtlinien beginnt die Annotation. Für beratungsorientierte Daten bedeutet das: Intent-Labels (Suchen, Vergleichen, Kaufen), Kontext-Tags (Budget, Zeitrahmen, Präferenzen), Attribut-Extraktion (Produkteigenschaften), und Qualitätsbewertung (War die Antwort hilfreich?).
Schritt 4: Kontinuierliche Qualitätssicherung
Qualitätskontrolle ist kein einmaliger Schritt, sondern ein kontinuierlicher Prozess. Inter-Annotator-Agreement-Metriken zeigen, wie konsistent verschiedene Annotatoren arbeiten. Feedback-Schleifen zwischen Annotatoren und Experten verbessern die Richtlinien über Zeit.
Schritt 5: Active Learning Feedback
Das trainierte Modell selbst wird zur Feedback-Quelle. Wo macht es Fehler? Welche Annotationen waren offensichtlich falsch? Diese Informationen fließen zurück in die Richtlinien und schaffen einen Kreislauf kontinuierlicher Verbesserung.
Lass deine KI von echten Fachleuten lernen. Unser Team übernimmt den gesamten Annotationsprozess – von der Richtlinien-Definition bis zur fertigen Trainingsdatenbank.
Jetzt Beratung anfragenPraxisbeispiele: Wo Annotation den Unterschied macht
Die praktische Anwendung von KI-Datenannotation zeigt sich in verschiedenen Bereichen. Je nach Branche und Anwendungsfall variieren die Anforderungen an Annotationsqualität und -tiefe erheblich.
Bildverarbeitung in E-Commerce und Industrie
Im Bereich der Bildverarbeitung nutzen Unternehmen Annotationstools für die präzise Kennzeichnung von Produktbildern. Die automatische Erkennung von Produktmerkmalen verbessert die Qualität der Beratung erheblich. Typische Anwendungen umfassen die automatische Qualitätskontrolle zur Erkennung von Produktfehlern, die KI-gestützte Produktkategorisierung und Sortierung von Artikelbildern, sowie die automatische Merkmalsextraktion von Produkteigenschaften.
Mit Standard-Tools wie Labelbox können Unternehmen Produktbilder intern labeln. Dies erfordert geschulte Mitarbeiter und manuelle Qualitätssicherung. Für rein visuelle Annotation – etwa das Markieren von Kratzen auf Oberflächen oder das Klassifizieren von Produktkategorien – ist dieser Ansatz durchaus praktikabel.
Textanalyse für Kundeninteraktion
Die Textanalyse profitiert von präzise gekennzeichneten Daten. Typische Anwendungen sind die Verarbeitung von Kundenfeedback, Support-Anfragen und Produktbeschreibungen. KI-Modelle lernen aus den gekennzeichneten Daten, Kundenintentionen und Stimmungen zu erkennen.
Hier zeigt sich jedoch der Unterschied: Einfache Sentiment-Analyse (positiv/negativ) lässt sich mit Standard-Tools gut annotieren. Sobald es um die Interpretation von Kundenaussagen geht – Was will der Kunde wirklich? Welches Produkt passt zu seinem Bedarf? – reicht oberflächliche Annotation nicht mehr aus.
Branchenlösungen: Vom Retail bis zum Gesundheitswesen
Verschiedene Branchen haben unterschiedliche Annotationsanforderungen. Im Einzelhandel verbessert präzise Annotation die Produkterkennung und Inventarisierung. Im Gesundheitswesen unterstützt sie bei der Analyse medizinischer Bilder – hier ist Experten-Annotation aus regulatorischen und Qualitätsgründen ohnehin Pflicht. Die Fertigungsindustrie nutzt Annotation für die Qualitätskontrolle in der Produktion.
Ob E-Commerce, Gesundheitswesen oder Industrie – in allen Bereichen sind hochwertige Trainingsdaten entscheidend für den Erfolg von KI-Modellen. Die Frage ist nicht ob annotiert werden muss, sondern wie gut und von wem.
Implementierungsguide: So startest du richtig
Die erfolgreiche Einführung einer KI-Datenannotation erfordert eine strukturierte Vorgehensweise. Ein gründlicher Setup-Prozess bildet das Fundament für effiziente Annotation. Die Integration in bestehende Machine Learning Workflows ermöglicht eine nahtlose Zusammenarbeit zwischen Teams und Systemen.
Setup und Projektaufbau
Der erste Schritt besteht in der technischen Einrichtung der Plattform oder des Prozesses. Dabei wird die Dateninfrastruktur konfiguriert und an die spezifischen Projektanforderungen angepasst. Die Basis-Konfiguration umfasst die Anbindung von Datenspeichern, die Definition von Annotationsrichtlinien und die Einrichtung von Qualitätskontrollmechanismen.
Teamstruktur und Rollenverteilung
Eine klare Rollenverteilung im Team ist für den Projekterfolg entscheidend. Die Kernrollen umfassen Projektmanager für die Koordination und Überwachung der Kennzeichnungsprozesse, Annotationsexperten für die Durchführung der eigentlichen Datenkennzeichnung, Qualitätsprüfer für die Sicherstellung der Datenqualität, und KI-Entwickler für die Integration der gekennzeichneten Daten in ML-Modelle. Eine gute Kommunikationsstruktur zwischen den Teams fördert die Effizienz des Annotationsprozesses.
Prozessoptimierung für kontinuierliche Verbesserung
Die kontinuierliche Verbesserung der Arbeitsabläufe steht im Zentrum der Prozessoptimierung. Durch regelmäßige Analysen der Annotationsqualität und Durchlaufzeiten können Engpässe identifiziert und beseitigt werden. Die Integration automatisierter Prüfprozesse hilft, die Qualität der Datenkennzeichnung konstant hoch zu halten.
Die Build-vs-Buy-Entscheidung
Das interne Labeling bringt erhebliche Herausforderungen mit sich. Hohe Personalkosten, lange Bearbeitungszeiten und die Notwendigkeit von Qualitätskontrollen können die Skalierbarkeit und Effizienz von KI-Projekten einschränken. Unternehmen müssen entscheiden: Intern aufbauen oder extern vergeben?
- Interne Annotation: Volle Kontrolle, aber hohe Fixkosten und Anlaufzeit
- Crowd-Sourcing: Günstig und skalierbar, aber Qualitätsprobleme bei komplexen Aufgaben
- Managed Services: Höhere Qualität, aber weniger direkte Kontrolle
- Hybrid-Ansatz: Kombination aus internem Experten-Kern und externem Scale
Die Alternative: Done-for-You statt DIY
Labelbox und ähnliche Tools sind eine ausgezeichnete Wahl für Unternehmen, die ihre Daten selbst labeln wollen und entsprechende Ressourcen bereitstellen können. Doch wenn du Zeit und Kosten sparen sowie eine höhere Qualität der Datenannotation sicherstellen möchtest, gibt es eine Alternative zum DIY-Ansatz.
Mit einem Done-for-You-Ansatz übernimmt ein spezialisierter Partner den gesamten Labeling-Prozess – schnell, skalierbar und mit höchster Qualität. Statt ein internes Team aufzubauen, Richtlinien zu entwickeln und Qualitätskontrolle zu implementieren, konzentrierst du dich auf das, was wirklich zählt: die Entwicklung und Verbesserung deiner KI-Modelle.
Die Investition in eine professionelle Datenkennzeichnung zahlt sich durch präzisere ML-Modelle und effizientere Entwicklungsprozesse aus. Mit der richtigen Strategie und einem strukturierten Vorgehen lässt sich der maximale Nutzen aus KI-Projekten ziehen – ohne den Overhead eines internen Annotationsteams.
Fazit: Gute Annotation macht den Chatbot zum Berater
KI-Datenannotation ist weit mehr als das simple Markieren von Objekten in Bildern. Für beratungsintensive Anwendungen – von der Produktempfehlung bis zum Kundenservice – entscheidet die Qualität der Annotation direkt über den Geschäftserfolg. Standard-Tools wie Labelbox bieten hervorragende Infrastruktur, aber für die Nuancen menschlicher Beratung braucht es mehr.
Die Kombination aus leistungsfähigen Annotationstools, umfassenden Qualitätskontrollmechanismen und vor allem Domänen-Expertise macht den Unterschied. Es geht nicht um die Masse der Daten, sondern um ihre Qualität und Relevanz für deinen spezifischen Anwendungsfall.
Das Potenzial der KI-Datenannotation wird durch kontinuierliche Weiterentwicklungen stetig ausgebaut. Für Unternehmen, die ihre KI-Entwicklung professionalisieren möchten, ist die Wahl des richtigen Annotationsansatzes eine strategische Entscheidung mit langfristigen Auswirkungen.
Der Unterschied zwischen einem simplen Chatbot und einem echten digitalen Berater liegt nicht im Algorithmus – er liegt in den Daten, von denen er lernt. Und die Qualität dieser Daten bestimmt sich durch die Qualität der Annotation.
FAQ: Häufige Fragen zur KI-Datenannotation
Die Kosten variieren stark je nach Datentyp und Komplexität. Einfache Bild-Annotation via Crowd-Sourcing kann bei wenigen Cent pro Label liegen. Experten-Annotation für beratungsintensive Dialoge kostet deutlich mehr, liefert aber auch signifikant bessere Modellqualität. ROI sollte immer gegen die Kosten schlechter Trainingsdaten gerechnet werden.
Die Antwort lautet: Es kommt darauf an. Für einfache Klassifizierungsaufgaben reichen oft wenige tausend Beispiele. Für komplexe Beratungsszenarien können 100 hochwertig annotierte Dialoge mehr Wert haben als 10.000 oberflächlich gelabelte. Qualität schlägt Quantität.
Für einfache, repetitive Aufgaben ja – Model-Assisted Labeling kann die Effizienz deutlich steigern. Für komplexe Aufgaben, die Domänenwissen erfordern, bleibt der Mensch unverzichtbar. Die beste Strategie ist meist ein Hybrid: Automatisierung für die Masse, Experten für die schwierigen Fälle.
Die Begriffe werden oft synonym verwendet. Technisch ist Labeling das Zuweisen von Kategorien oder Tags, während Annotation den breiteren Prozess beschreibt, der auch Markierungen, Segmentierungen und Metadaten umfasst. Für die Praxis ist die Unterscheidung meist irrelevant.
Die Dauer hängt von Datenmenge, Komplexität und Team-Setup ab. Ein kleines Pilotprojekt kann in wenigen Wochen fertig sein. Enterprise-Scale-Projekte laufen oft kontinuierlich, da neue Daten laufend annotiert werden müssen. Wichtig ist ein realistischer Zeitplan mit Puffer für Qualitätssicherung.
Lass uns gemeinsam deine KI-Projekte auf das nächste Level heben. Wir übernehmen die gesamte Datenkennzeichnung, sodass du dich voll auf die Modellentwicklung konzentrieren kannst.
Kostenlose Beratung starten
Kevin ist CTO und Mitgründer von Qualimero. Als KI-Architekt mit über 15 Jahren Erfahrung als CTO und CPO in der Tech-Branche entwirft er die KI-Systeme, die bei Qualimeros Kunden täglich zehntausende Kundeninteraktionen automatisieren — zuverlässig, sicher und skalierbar.
