Was ist eine Vektordatenbank? Definition und Grundlagen
Eine Vektordatenbank ist ein spezialisiertes Datenbanksystem, das Informationen als hochdimensionale Vektoren speichert und per Ähnlichkeitssuche abrufbar macht. Anders als relationale Datenbanken, die exakte Treffer liefern, findet eine Vektordatenbank konzeptionell ähnliche Datenpunkte, indem sie deren Nähe im mathematischen Vektorraum berechnet. Damit bildet sie die Grundlage für semantische Suche, Empfehlungssysteme und moderne KI-Anwendungen wie Retrieval Augmented Generation (RAG).
Der Schlüssel zum Verständnis: Jede Information, ob Text, Bild oder Produktbeschreibung, wird durch ein sogenanntes Embedding in eine Reihe von Zahlen umgewandelt. Ein modernes Embedding-Modell erzeugt Vektoren mit bis zu 1.536 Dimensionen. Jede Dimension kodiert einen Bedeutungsaspekt. Zwei ähnliche Konzepte landen im Vektorraum nah beieinander, zwei grundverschiedene weit auseinander.
Stell dir einen Online-Shop mit 5.000 Gartenprodukten vor. Ein Kunde tippt: Mein Rasen hat braune Stellen nach dem Winter. Eine klassische Suche findet das Wort Rasen und zeigt alles von Rasenmähern bis Rasenkantensteine. Die Vektordatenbank versteht das Konzept Rasenreparatur nach Frostschaden und liefert gezielt Nachsaat, Rasendünger und Bodenaktivator.
Warum der Hype gerade jetzt? Bis 2023 waren Vektordatenbanken ein Nischenthema für Machine-Learning-Ingenieure. Mit dem Durchbruch von Large Language Models wie GPT-4 brauchte plötzlich jedes Unternehmen eine Möglichkeit, eigene Daten an KI-Modelle anzubinden. Vektordatenbanken sind genau diese Brücke. Laut Fortune Business Insights wächst der Markt von 2,6 Mrd. USD im Jahr 2025 auf über 17,9 Mrd. USD bis 2034.
Ein konkretes Beispiel verdeutlicht den Mechanismus. Das Wort Apfel und das Wort Birne liegen im Vektorraum nah beieinander, weil beide Früchte sind. Apfel und iPhone liegen ebenfalls nicht weit auseinander, weil der Kontext sie verbindet. Aber Apfel als Frucht und Apfel als Technologieprodukt bekommen je nach Kontext der Anfrage unterschiedliche Vektoren zugewiesen. Diese kontextabhängige Vektorisierung ist der Grund, warum moderne Embedding-Modelle klassische Keyword-Systeme übertreffen.
Quelle: Fortune Business Insights
Prognose 2025 bis 2034
Quelle: Fortune Business Insights
Standard bei aktuellen Embedding-Modellen
Wie funktioniert eine Vektordatenbank?
Drei Schritte, ein Ergebnis. So verarbeitet eine Vektordatenbank jede Anfrage, von der Produktsuche bis zur RAG-Abfrage.
Ein Embedding-Modell wandelt Rohdaten (Text, Bilder, Produktattribute) in numerische Vektoren um. Jeder Vektor repräsentiert die semantische Bedeutung des Datenpunkts in hunderten oder tausenden Dimensionen.
Algorithmen wie HNSW (Hierarchical Navigable Small World) oder IVF (Inverted File Index) organisieren die Vektoren für schnellen Zugriff. Statt jeden einzelnen Vektor zu vergleichen, durchsuchen sie effiziente Nachbarschaftsstrukturen.
Bei einer Anfrage wird der Suchbegriff ebenfalls vektorisiert. Die Datenbank berechnet die Nähe zwischen Abfragevektor und gespeicherten Vektoren per Kosinus-Ähnlichkeit, euklidischem Abstand oder Skalarprodukt.
Die Wahl der Distanzmetrik beeinflusst die Ergebnisqualität direkt. Kosinus-Ähnlichkeit misst den Winkel zwischen zwei Vektoren und eignet sich für Textvergleiche. Euklidischer Abstand misst die tatsächliche Distanz im Raum und passt besser für Bild- oder Audiodaten. Das Skalarprodukt (Dot Product) kombiniert Richtung und Magnitude und wird häufig bei normalisierten Embeddings eingesetzt.
HNSW ist der aktuell verbreitetste Indexierungsalgorithmus. Er baut eine Graphstruktur mit mehreren Ebenen auf, ähnlich einer Landkarte mit unterschiedlichen Zoomstufen. Auf der obersten Ebene sind nur wenige, weit verteilte Knotenpunkte sichtbar. Mit jeder Ebene wird das Netz feiner. So findet der Algorithmus die nächsten Nachbarn in logarithmischer Zeit, ohne alle Vektoren einzeln prüfen zu müssen.
Neben HNSW gibt es den IVF-Ansatz (Inverted File Index), der den Vektorraum in Cluster aufteilt und nur die relevantesten Cluster durchsucht. IVF ist speichereffizienter, aber weniger präzise als HNSW. Die Wahl hängt vom Anwendungsfall ab: Für Echtzeitanfragen in einem Shop mit 50.000 Produkten ist HNSW die bessere Wahl. Für Batch-Analysen über Millionen von Dokumenten kann IVF der effizientere Weg sein.
Das Ergebnis: Antwortzeiten im einstelligen Millisekundenbereich, selbst bei Millionen von Vektoren. AWS berichtet für seinen MemoryDB-Dienst von über 99% Recall bei zehntausenden Abfragen pro Sekunde. Für die Praxis bedeutet das: Eine Produktsuche mit semantischem Verständnis dauert nicht länger als eine klassische Datenbankabfrage.
Ein oft übersehener Aspekt: Speicheroptimierung durch Quantisierung. Ein einzelner Vektor mit 384 Dimensionen belegt etwa 1,5 KB Speicher. Bei 100 Millionen Dokumenten wächst der Index um den Faktor sieben allein durch das Vektorfeld. Skalare Quantisierung reduziert den Speicherbedarf um das Vierfache, binäre Quantisierung sogar um das 32-Fache. Für KMU mit begrenztem Infrastrukturbudget ist das ein entscheidender Kostenfaktor.
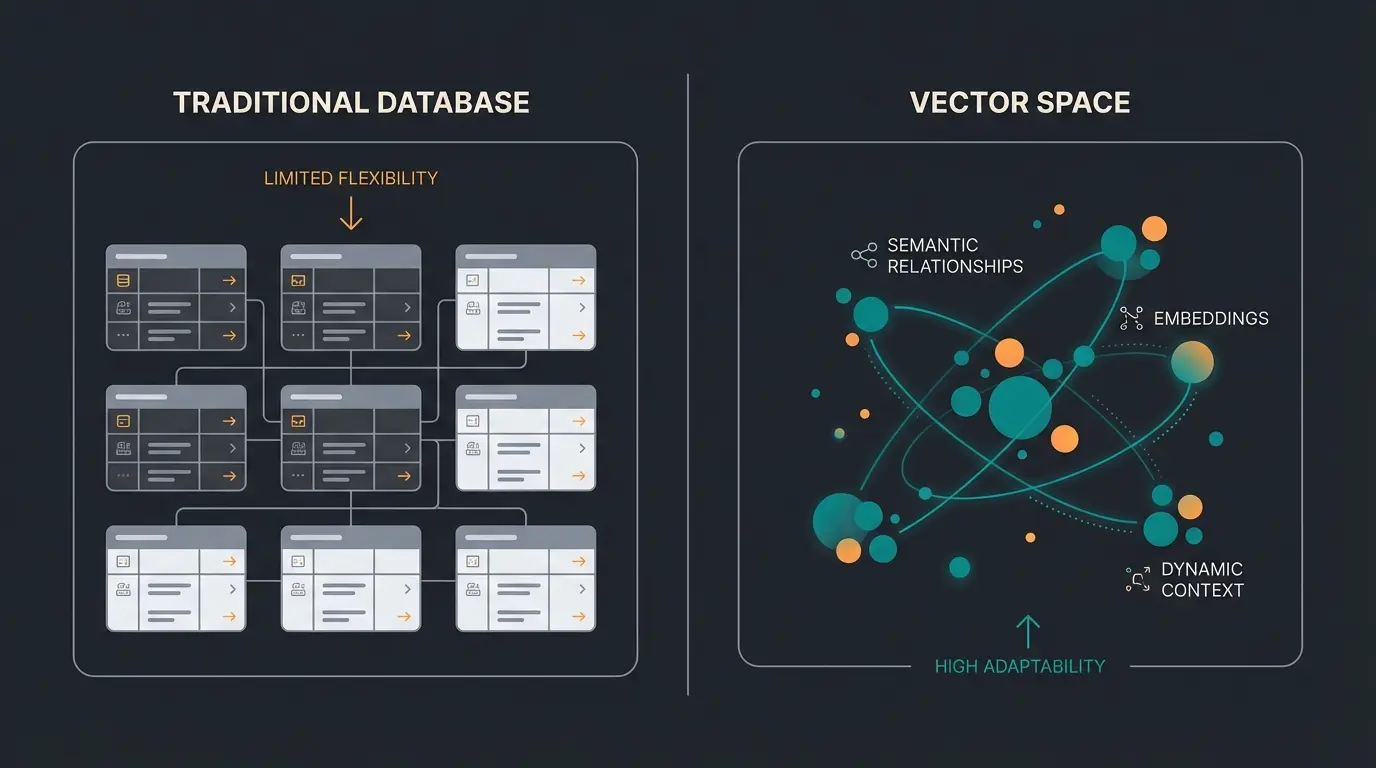
Vektordatenbank vs. relationale Datenbank: Die wichtigsten Unterschiede
Die Frage kommt in jedem zweiten Kundengespräch: Warum reicht meine PostgreSQL-Datenbank nicht? Die kurze Antwort: Für strukturierte Abfragen wie Zeige alle Schuhe in Größe 42 unter 100 EUR reicht sie vollkommen. Für semantische Abfragen wie Bequeme Schuhe fürs Büro, nicht zu sportlich braucht es eine andere Architektur.
| Merkmal | Relationale Datenbank | Vektordatenbank |
|---|---|---|
| Datenmodell | Strukturierte Tabellen mit Zeilen und Spalten | Hochdimensionale Vektoren (Embeddings) |
| Abfragetyp | Exakte Treffer per SQL (WHERE, JOIN) | Ähnlichkeitssuche per Distanzberechnung |
| Suchlogik | Schlüsselwort-basiert: findet nur exakte Übereinstimmungen | Semantisch: versteht Bedeutung und Kontext |
| Datentypen | Strukturierte Daten (Zahlen, Strings, Datum) | Unstrukturierte Daten (Text, Bild, Audio) |
| Skalierung | Vertikal oder horizontal mit Sharding | Horizontal mit spezialisierten Indexstrukturen (HNSW, IVF) |
| Typischer Einsatz | ERP, CRM, Buchhaltung, Bestandsverwaltung | Semantische Suche, RAG, Empfehlungssysteme, KI-Anwendungen |
| Konsistenzmodell | ACID (strenge Konsistenz) | Oft BASE (Eventual Consistency) |
Die Entscheidung relational oder Vektor ist in der Praxis selten ein Entweder-oder. Die meisten produktiven Systeme kombinieren beide Ansätze. Der Produktkatalog mit Preisen, Verfügbarkeiten und Bestellhistorie liegt in der relationalen Datenbank. Die semantischen Repräsentationen der Produktbeschreibungen, Kundenbewertungen und Beratungsinhalte liegen in der Vektordatenbank. Beide Systeme ergänzen sich bei jeder Suchanfrage.
In der Praxis schließen sich beide Systeme nicht aus. Die interessanteste Entwicklung 2026: pgvector bringt Vektorfähigkeiten direkt in PostgreSQL. Wer bereits eine relationale Datenbank betreibt, muss kein separates System aufsetzen, sondern aktiviert eine Extension und kann sofort Vektoren speichern und durchsuchen.
Eine Einschränkung ist wichtig: Vektordatenbanken ersetzen keine relationale Datenbank. Sie ergänzen sie. Produktpreise, Lagerbestände und Kundenkonten gehören weiterhin in eine klassische Datenbank. Die Vektordatenbank übernimmt das, was SQL nicht kann: Bedeutung verstehen.
Top Vektordatenbanken im Vergleich 2026
Der Markt hat sich konsolidiert. Statt hundert Nischenprojekten gibt es eine Handvoll ernstzunehmender Lösungen, die 2026 im produktiven Einsatz stehen. Hier der aktuelle Stand, sortiert nach Relevanz für KMU im DACH-Raum.
| Lösung | Typ | Stärken | Am besten für | Preismodell |
|---|---|---|---|---|
| Qdrant | Open Source + Cloud | Rust-basiert, hohe Performance, HNSW-Index, starke API-Dokumentation | KMU und Enterprises mit eigener Infrastruktur | Free (self-hosted), Cloud ab 25 USD/Monat |
| Pinecone | Managed Service | Einfaches Setup, geringe Latenz, Serverless-Architektur | Teams ohne Infrastruktur-Expertise | Free Tier, Pro ab 70 USD/Monat |
| Weaviate | Open Source + Cloud | GraphQL-API, eingebaute Vektorisierung, hybride Suche | Entwicklerteams, schnelle Prototypen | Free (self-hosted), Cloud ab 25 USD/Monat |
| Chroma | Open Source | Leichtgewichtig, Python-nativ, einfache Integration | Lokale Entwicklung, kleine RAG-Projekte | Kostenlos (Open Source) |
| Milvus | Open Source | Hochgradig skalierbar, GPU-Beschleunigung, reife Community | Große Datenmengen, Enterprise-Workloads | Free (self-hosted), Zilliz Cloud verfügbar |
| pgvector | PostgreSQL-Extension | Nahtlose Integration in PostgreSQL, HNSW seit v0.7.0, bekannte Tools | KMU mit bestehender PostgreSQL-Infrastruktur | Kostenlos (Extension) |
| Elasticsearch | Kommerziell + OSS | Volltext- und Vektorsuche kombiniert, reifes Ökosystem | Unternehmen mit bestehender Elastic-Infrastruktur | Free (Basic), Enterprise-Lizenz |
Die Unterscheidung zwischen einer Vektorbibliothek und einer Vektordatenbank ist entscheidend. FAISS von Meta oder Annoy von Spotify sind reine Suchalgorithmen ohne Persistenz, API oder Zugriffsmanagement. Für Produktionsumgebungen, in denen Daten gespeichert, aktualisiert und parallel abgefragt werden, braucht es eine vollwertige Datenbank.
Für Unternehmen mit höheren Anforderungen an Performance oder Skalierung empfehle ich Qdrant. Rust-basiert, Open Source und mit einer der aktivsten Communities im Vektordatenbank-Bereich. Qdrant lässt sich auf eigenen Servern in der EU betreiben, was für Unternehmen mit strengen Datenschutzanforderungen den Ausschlag gibt.
Ein Wort zur DSGVO-Konformität: Managed Services wie Pinecone speichern Daten auf US-Servern. Für Unternehmen mit strengen Datenschutzanforderungen ist das problematisch. Selbst gehostete Lösungen wie Qdrant, Milvus oder pgvector lassen sich auf EU-Infrastruktur betreiben. Das ist kein Nischenthema: Im DACH-Raum sehe ich zunehmend Unternehmen, die sich explizit für eine self-hosted Lösung entscheiden, weil ihre Kunden personalisierte Beratung erwarten, aber keine Datenweitergabe in Drittländer akzeptieren.
Anwendungsbereiche: Wo Vektordatenbanken den Unterschied machen
Fünf Anwendungsfälle, die 2026 in fast jedem KI-Projekt auftauchen.
- Semantische Suche: Statt Schlüsselwörter abzugleichen, versteht die Vektordatenbank die Absicht hinter einer Suchanfrage. Leichter Laufschuh für Asphalt liefert relevante Ergebnisse, auch wenn kein Produkt exakt diese Wörter enthält.
- Empfehlungssysteme und Produktberatung: Die Vektordatenbank berechnet Ähnlichkeiten zwischen Kundenpräferenzen und Produktattributen in Echtzeit. Im E-Commerce führt das zu Empfehlungen, die sich wie echte Beratung anfühlen, nicht wie generische Kunden kauften auch-Listen.
- RAG für KI-Assistenten: Large Language Models wie GPT-4 oder Claude wissen nur, was in ihren Trainingsdaten steht. Per Retrieval Augmented Generation greift die KI auf eine Vektordatenbank mit aktuellen Unternehmensdaten zu. Das Ergebnis: weniger Halluzinationen, kontextgenaue Antworten.
- Bild- und Videosuche: Computer-Vision-Modelle erzeugen Embeddings für visuelle Inhalte. Kunden laden ein Foto hoch und erhalten visuell ähnliche Produkte, ohne den Stil in Worte fassen zu müssen.
- Anomalie-Erkennung: In der Finanz- und IT-Sicherheit identifizieren Vektordatenbanken Muster, die von der Norm abweichen. Ein Datenpunkt, der weit von seinen Nachbarn im Vektorraum liegt, signalisiert potentiellen Betrug oder einen Systemfehler.
Ein wachsender Trend 2026: multimodale Embeddings. Statt nur Text oder nur Bilder zu vektorisieren, erzeugen Modelle wie CLIP oder Gemini Embeddings, die Text und Bild in einem gemeinsamen Vektorraum abbilden. Ein Kunde kann ein Foto von einer Pflanzenkrankheit hochladen, und die Vektordatenbank findet sowohl visuell ähnliche Krankheitsbilder als auch die passenden Textanleitungen zur Behandlung. Diese Konvergenz von Text- und Bildverständnis eröffnet E-Commerce-Anwendungen, die vor zwei Jahren noch Science Fiction waren.
Semantische Suche vs. Keyword-Suche: ein konkretes Beispiel
Ein Kunde sucht in einem Baumarkt-Shop nach Winterjacke nicht zu schwer. Die klassische Keyword-Suche findet das Wort schwer und zeigt möglicherweise schwere Jacken an, das Gegenteil vom Gewünschten. Die Vektordatenbank ordnet die Anfrage im Bedeutungsraum ein und versteht das Konzept leichte Isolierung. Sie präsentiert High-Tech-Daunenjacken mit modernem Thermomaterial.
Dieser Unterschied ist nicht akademisch. Er entscheidet darüber, ob ein Kunde das Produkt findet, das er sucht, oder den Shop verlässt. In beratungsintensiven Sortimenten wie Pflanzenschutz, Nahrungsergänzung oder technischem Equipment ist semantisches Verständnis keine Option, sondern Voraussetzung für eine brauchbare Suche.
Hybrid Search: Semantik und Faktenfilter kombinieren
In der Praxis reicht reine Vektorsuche für Produktdaten nicht aus. Ein Kunde sucht einen stylischen Schuh, aber in Größe 42. Die Vektordatenbank findet den perfekt stylischen Schuh, aber in Größe 38. Ohne Faktenfilter ist das Ergebnis nutzlos. Hybrid Search löst dieses Problem: Die Vektorsuche kümmert sich um den Stil, die Keyword-Filter kümmern sich um Größe, Preis und Verfügbarkeit.
Diese Kombination ist der Industriestandard 2026. Pinecone, Qdrant und Elasticsearch unterstützen hybride Abfragen nativ. Weaviate kombiniert BM25-Scoring mit Vektor-Scoring in einer einzigen Anfrage. Für E-Commerce-Anwendungen ist Hybrid Search keine optionale Erweiterung, sondern das Minimum für brauchbare Ergebnisse.
Für E-Commerce-Unternehmen sind besonders die ersten drei Anwendungsfälle relevant. KI-gestützter Vertrieb kombiniert Produktberatung mit Echtzeitdaten aus der Vektordatenbank. Conversational Commerce setzt auf semantisches Produktverständnis statt starrer Entscheidungsbäume. Und Kundenservice Automatisierung profitiert von RAG-basierten Wissensdatenbanken, die Kundenanfragen ohne manuelles Regelwerk beantworten.
Im DACH-Raum sehe ich den stärksten Anstieg bei RAG-Anwendungen. Unternehmen, die ihre Produktdaten, Handbücher und Schulungsunterlagen in eine Vektordatenbank überführen, können innerhalb von Wochen einen KI-Mitarbeiter aufbauen, der diese Informationen in natürlicher Sprache abrufbar macht. Kein monatelanges Regelwerk-Bauen, kein manuelles Pflegen von Antwortvorlagen.
Vektordatenbanken und RAG: Das Langzeitgedächtnis für KI-Assistenten
Retrieval Augmented Generation, kurz RAG, ist das Architekturprinzip, das Vektordatenbanken 2026 zum Mainstream gemacht hat. Ein Large Language Model generiert Antworten nicht nur aus seinem Trainingswissen, sondern bezieht aktuelle, unternehmensspezifische Daten aus einer Vektordatenbank ein. Das macht den Unterschied zwischen einer generischen KI und einem KI-Mitarbeiter, der wie ein echtes Teammitglied agiert.
Die Zahlen verdeutlichen den Nutzen. Ohne RAG produzieren Sprachmodelle bei unternehmensspezifischen Fragen eine Halluzinationsrate von bis zu 30%. Mit einer gut gepflegten Vektordatenbank als Wissensbasis sinkt diese Rate auf unter 5%. Für Unternehmen, die KI im Kundenkontakt einsetzen, ist das der Unterschied zwischen einem nützlichen Werkzeug und einem Haftungsrisiko.
Unternehmensdaten (Produktkatalog, Handbücher, FAQs) werden in Textabschnitte aufgeteilt und per Embedding-Modell in Vektoren umgewandelt.
Die Embeddings werden indexiert und gespeichert. Metadaten wie Kategorie, Datum und Quelle ermöglichen zusätzliche Filterung neben der semantischen Suche.
Die Anfrage wird ebenfalls vektorisiert. Die Datenbank findet die semantisch relevantesten Dokument-Abschnitte per Ähnlichkeitssuche.
Das LLM erhält die gefundenen Abschnitte als Kontext und generiert eine präzise, faktenbasierte Antwort statt zu halluzinieren.
Der entscheidende Vorteil gegenüber einem Finetuning des Sprachmodells: Die Wissensbasis lässt sich jederzeit aktualisieren, ohne das Modell neu zu trainieren. Ein neues Produkt im Katalog? Es wird vektorisiert und ist sofort abrufbar. Eine geänderte Rückgabebedingung? Die KI kennt sie ab der nächsten Anfrage. Kein erneutes Training, keine Wartezeit.
Wie diese Architektur in der Praxis funktioniert, erklärt der Artikel zur Funktionsweise von KI-Assistenten im Detail. Der Unterschied zwischen einem regelbasierten System und einem RAG-gestützten KI-Mitarbeiter ist fundamental: Regeln decken nur vorhersehbare Anfragen ab. RAG versteht auch Fragen, die noch niemand formuliert hat.
Ein reales Beispiel aus dem E-Commerce: Ein Online-Gartenfachhandel speist seinen gesamten Produktkatalog, alle Pflegeanleitungen und saisonale Beratungstipps in eine Vektordatenbank ein. Wenn ein Kunde fragt Welchen Dünger braucht mein Kirschbaum im März?, findet die RAG-Pipeline die passende Pflegeanleitung für Steinobst, den empfohlenen Dünger für Frühjahr und die richtige Dosierung. Die KI formuliert eine zusammenhängende Antwort, die alle drei Informationsquellen verknüpft.
Ohne RAG hätte das Sprachmodell entweder generisch geantwortet oder halluziniert. Mit RAG antwortet es präzise, aktuell und auf Basis der tatsächlichen Produkte im Sortiment. Die Vektordatenbank macht den Unterschied zwischen einer KI, die rät, und einer KI, die berät.
Vektordatenbanken im E-Commerce: Von der Suche zur Beratung
Ich habe letzte Woche mit einem Shopware-Händler gesprochen, der 12.000 Produkte im Sortiment hat. Seine interne Suche liefert bei Pflanzenschutz ohne Chemie null Treffer, obwohl er biologische Pflanzenstärkungsmittel im Programm hat. Das ist kein Einzelfall. Es ist der Normalzustand im deutschen E-Commerce.
Eine Vektordatenbank ändert die Spielregeln. Sie versteht, dass ohne Chemie semantisch zu biologisch und natürlich gehört. Sie erkennt, dass ein Kunde, der etwas gegen Blattläuse, aber sicher für Kinder sucht, Nützlinge oder biologische Sprays braucht. Diese Art der semantischen Produktsuche ist der erste Schritt. Echte Beratung geht weiter: Die KI führt einen Dialog, fragt nach und erklärt, warum ein bestimmtes Produkt passt.
Bei Qualimero setzen wir Vektordatenbanken als Kern unserer KI-Mitarbeiter ein. Unsere KI-Mitarbeiterin Flora berät Kunden im Garten- und Pflanzenschutzbereich mit 97% Empfehlungsgenauigkeit und einer Kostenersparnis von 99,2% pro Interaktion gegenüber menschlicher Beratung. Wie verschiedene KI-Produktberatung Anbieter im Markt abschneiden, zeigt unser separater Vergleich.
Der Unterschied zwischen einer reinen Empfehlung und echter Beratung liegt in der Erklärung. Ein passives Empfehlungssystem zeigt Kunden kauften auch und überlässt den Kunden sich selbst. Ein KI-Mitarbeiter mit Vektordatenbank-Kern kann sagen: Dieses biologische Pflanzenstärkungsmittel empfehle ich dir, weil es gegen Blattläuse wirkt und gleichzeitig für Kinder und Haustiere unbedenklich ist. Das ist die Erklärung, die den Unterschied zwischen Stöbern und Kaufen macht.
Die Kombination aus Vektordatenbank und Hybrid Search ist dabei entscheidend. Die semantische Suche versteht den Kundenwunsch. Die Faktenfilter stellen sicher, dass nur lieferbare Produkte in der richtigen Kategorie empfohlen werden. Und die Business-Logic-Schicht übersetzt vage Begriffe wie natürlich oder für Anfänger in konkrete Produktattribute, ohne zu halluzinieren.
Qualimeros KI-Mitarbeiter nutzen Vektordatenbanken, um deine Kunden in Echtzeit zu beraten. +35% Warenkorbwert, +60% Checkout-Rate bei unseren Kunden. Kein Regelwerk, kein Flow-Builder.
Kostenlos testen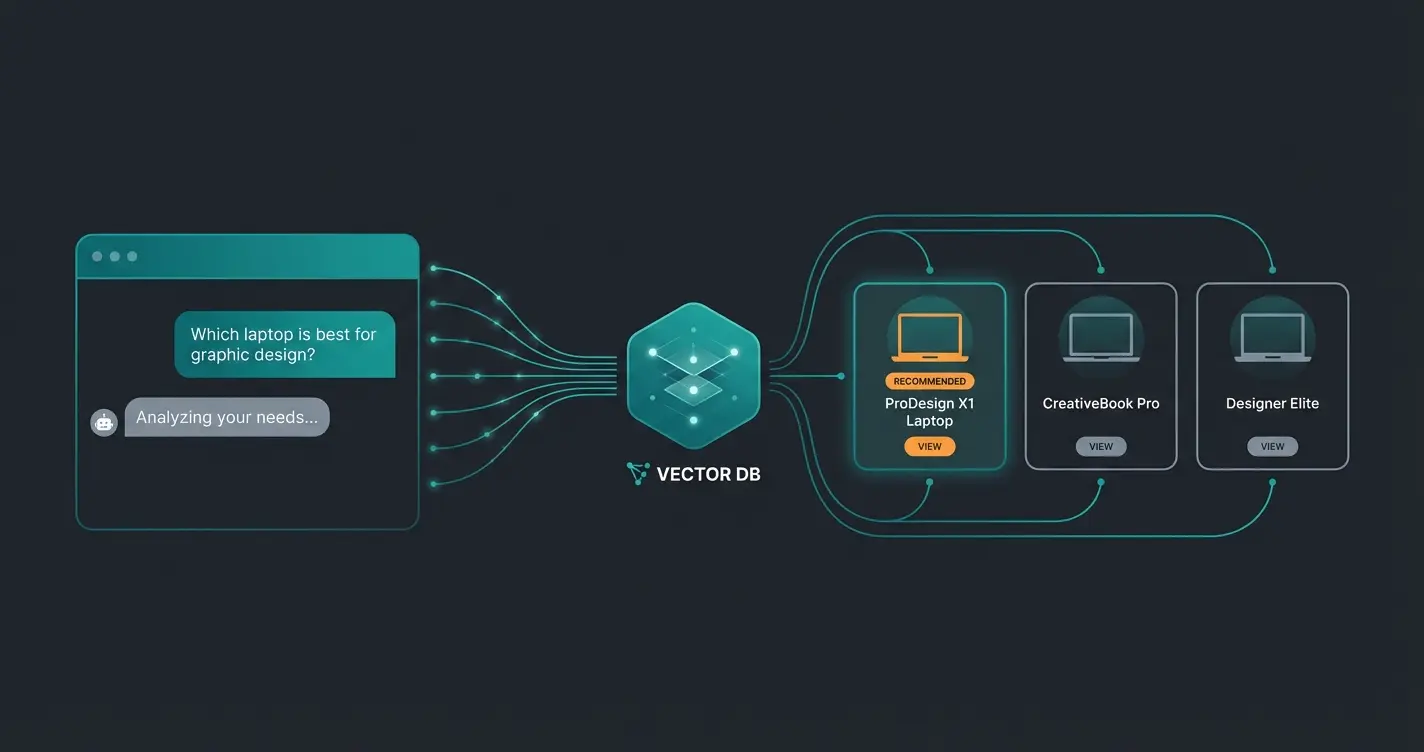
Implementierung: So starten KMU mit Vektordatenbanken
Drei Wege, sortiert nach Komplexität und Einstiegshürde.
- pgvector auf bestehendem PostgreSQL: Der niedrigste Einstieg. Wenn du bereits PostgreSQL nutzt, aktivierst du die pgvector-Extension und kannst sofort Vektoren speichern und durchsuchen. HNSW-Indexierung ist seit Version 0.7.0 verfügbar. Kein zusätzliches System, keine Migration, keine neuen Zugangsdaten.
- Managed Cloud-Service: Pinecone oder Qdrant Cloud bieten serverlose Vektordatenbanken mit wenigen Klicks. Vorteile: kein Infrastruktur-Management, automatische Skalierung, kostenlose Einstiegspläne. Der Nachteil: Daten liegen bei einem US-Anbieter, was DSGVO-Fragen aufwerfen kann.
- Self-Hosted Open Source: Qdrant, Milvus oder Weaviate lassen sich auf eigener Infrastruktur in der EU betreiben. Volle Kontrolle über Daten und Performance, aber höherer Betriebsaufwand. Für Unternehmen mit strengen Compliance-Anforderungen oder sehr großen Datenmengen die richtige Wahl.
Meine Empfehlung für die meisten KMU: Starte mit pgvector. Lerne, wie Embeddings funktionieren und wie sich Vektorsuche anfühlt. Wenn die Anforderungen wachsen, ist der Wechsel zu Qdrant oder Pinecone jederzeit möglich. Der häufigste Fehler, den ich sehe: Zu früh in eine Enterprise-Lösung investieren, bevor der Use Case validiert ist.
Und ja, Vektordatenbanken lösen nicht jedes Problem. Wenn dein Produktkatalog unter 100 Artikel umfasst und du keine natürlichsprachige Suche brauchst, ist eine einfache Volltextsuche günstiger und schneller. Die Technologie entfaltet ihren Wert ab einigen hundert Produkten oder bei komplexen, beratungsintensiven Sortimenten.
Die Kosten für den Einstieg sind überschaubar. pgvector als PostgreSQL-Extension ist kostenlos. Die Vektorisierung über OpenAIs Embedding-API kostet etwa 0,10 USD pro Million Tokens. Für einen Produktkatalog mit 5.000 Artikeln bedeutet das wenige Cent pro vollständiger Indexierung. Qdrant Cloud und Pinecone bieten kostenlose Einstiegspläne mit ausreichend Kapazität für Prototypen und kleine Produktivumgebungen. Die größte Investition ist nicht die Infrastruktur, sondern die Aufbereitung der Daten: saubere Produktbeschreibungen, strukturierte Attribute und konsistente Textqualität.
- Produktkatalog mit mehr als 100 Artikeln und strukturierten Beschreibungen
- Vorhandene PostgreSQL-Infrastruktur (oder Bereitschaft, eine aufzusetzen)
- Mindestens ein Use Case identifiziert: semantische Suche, Produktberatung oder RAG
- Budget für Embedding-API-Kosten (ca. 0,10 USD pro 1 Million Tokens bei OpenAI)
- Entwicklerkapazität für initiale Integration (1-2 Wochen für einen Prototyp)
Ein typischer Implementierungspfad für ein mittelständisches E-Commerce-Unternehmen: Woche 1, pgvector aktivieren und erste Produktbeschreibungen vektorisieren. Woche 2, semantische Suchfunktion als internes Testtool aufbauen. Woche 3-4, Ergebnisqualität evaluieren und Hybrid Search mit Faktenfiltern ergänzen. Ab Woche 5, produktiven Einsatz mit einer Produktkategorie starten und Ergebnisse messen.
Häufig gestellte Fragen zu Vektordatenbanken
Die wichtigsten Lösungen 2026 sind Qdrant, Pinecone, Weaviate, Chroma, Milvus, pgvector und Elasticsearch. Qdrant und Milvus sind Open Source und selbst hostbar. Pinecone ist ein reiner Managed Service. pgvector eignet sich besonders für Unternehmen, die bereits PostgreSQL einsetzen.
Eine Vektordatenbank speichert Informationen als mathematische Zahlenvektoren und findet ähnliche Datenpunkte per Distanzberechnung. Statt exakter Schlüsselwortsuche versteht sie Bedeutung und Kontext. So liefert sie bei der Suche nach bequemer Büroschuh relevante Ergebnisse, auch wenn kein Produkt exakt diese Wörter im Titel hat.
Im KI-Kontext dient eine Vektordatenbank als Langzeitgedächtnis für Sprachmodelle. Per Retrieval Augmented Generation (RAG) greift die KI auf aktuelle Unternehmensdaten zu, ohne dass das Modell neu trainiert werden muss. Das reduziert Halluzinationen und liefert faktenbasierte Antworten mit aktuellem Unternehmenskontext.
Daten werden per Embedding-Modell in hochdimensionale Vektoren umgewandelt. Indexierungsalgorithmen wie HNSW organisieren diese Vektoren für schnellen Zugriff. Bei einer Anfrage berechnet die Datenbank per Kosinus-Ähnlichkeit oder euklidischem Abstand, welche gespeicherten Vektoren der Anfrage am nächsten liegen.
SQL-Datenbanken eignen sich für strukturierte Abfragen mit exakten Filtern (Preis, Größe, Datum). Vektordatenbanken eignen sich für semantische Suche und Ähnlichkeitsabfragen. In der Praxis ergänzen sich beide. pgvector bringt Vektorfähigkeiten direkt in PostgreSQL, sodass du beides in einem System nutzen kannst.
Vektordatenbanken sind keine Zukunftstechnologie mehr. Sie sind die Infrastruktur, auf der 2026 jede ernstzunehmende KI-Anwendung aufbaut. Für KMU im DACH-Raum liegt die Einstiegshürde so niedrig wie nie: pgvector kostet nichts, Open-Source-Embedding-Modelle laufen auf jeder Standardhardware, und die Community um Qdrant, Weaviate und Milvus wächst monatlich. Der beste Zeitpunkt, mit einem Prototyp zu starten, war vor einem Jahr. Der zweitbeste ist jetzt.
Vektordatenbanken sind die Grundlage. Qualimeros KI-Mitarbeiter machen sie für deine Kunden nutzbar. Starte mit einer kostenlosen Demo und sieh, wie semantische Produktberatung in deinem Shop funktioniert.
Demo vereinbaren
Lasse ist CEO und Mitgründer von Qualimero. Nach seinem MBA an der WHU und dem Aufbau eines Unternehmens auf siebenstellige Umsätze gründete er Qualimero, um KI-gestützte digitale Mitarbeiter für den E-Commerce zu entwickeln. Sein Fokus: Unternehmen dabei unterstützen, Kundeninteraktion durch intelligente Automatisierung messbar zu verbessern.